
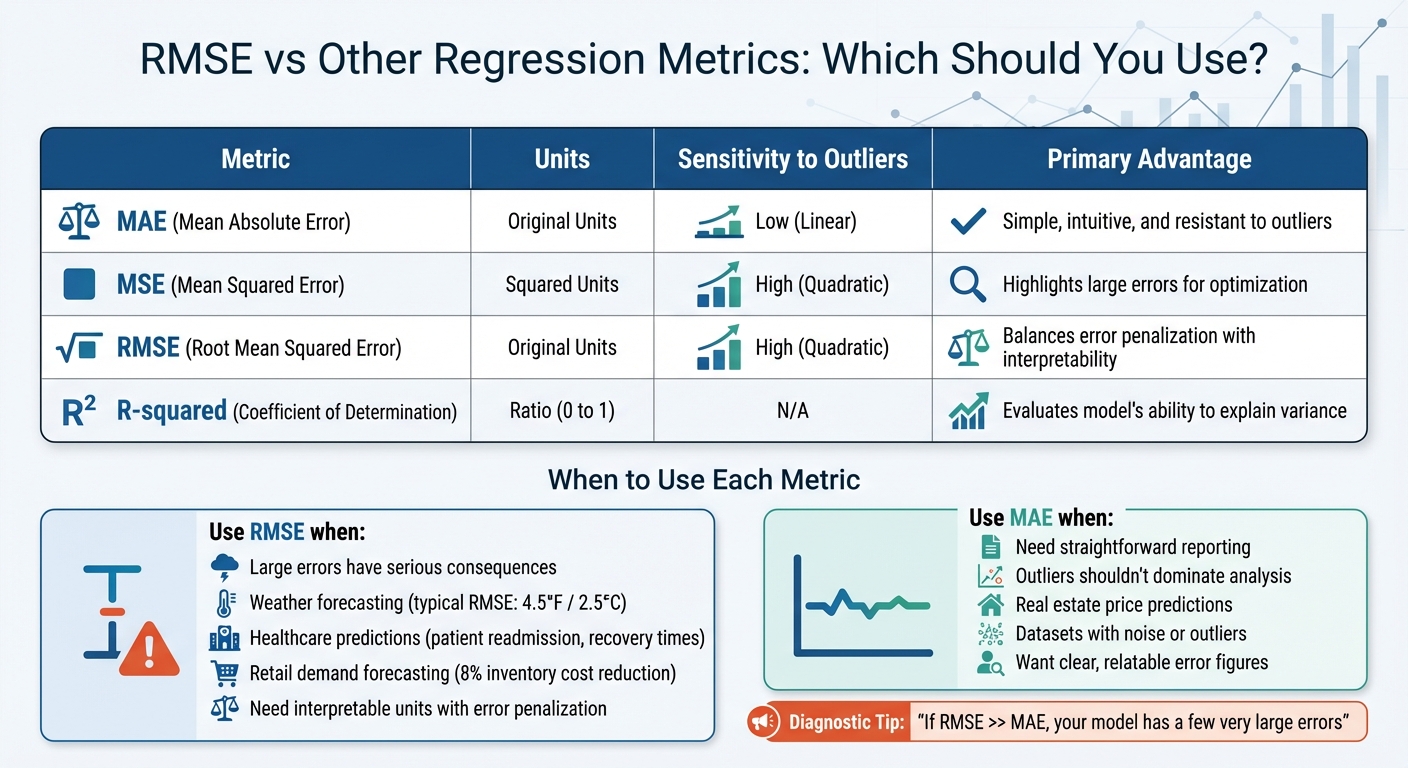
Look, I've seen machine learning engineers stare at a confusion matrix like it's a map to buried treasure. But when I ask them why they chose RMSE over EMQ (or vice versa), I usually get a blank stare followed by something like, “Because the tutorial said so.” Let's fix that right now. The statistical difference between EMQ and RMSE error metrics isn't a dusty footnote in a textbook—it's a practical decision that changes how you interpret model failure. And if you get it wrong, you could end up optimizing for the wrong thing entirely.
Honestly? Most people don't realize that EMQ (often confused with Mean Squared Error or a specific variant like Equivalent Mean Square) and RMSE (Root Mean Squared Error) share a parent but have radically different children. The core math is simple: RMSE is the square root of the mean of squared errors. EMQ is often just the mean of squared errors. That one operation—taking the square root—doesn't just scale the numbers. It changes the statistical distribution of the metric itself.
Let's dive in. Seriously. This matters way more than you think.
The Core Difference: Squaring vs. Square Rooting
When you compute EMQ (or MSE, for the purists), you're summing up all the squared differences between predictions and actuals, then dividing by the number of observations. The result lives in squared units. If your target variable is house prices in dollars, your EMQ is in dollars squared. That's abstract. Nobody walks around saying, “My model has an error of 1,500 dollars squared.” It sounds like a foreign language.
RMSE fixes that by pulling the square root. The result is back in the original units. Dollars. Meters. Likes. Whatever. That alone makes RMSE more interpretable for stakeholders who don't live in math-land. But the statistical difference between EMQ and RMSE error metrics goes deeper than interpretability.
Consider what happens to outliers. A single bad prediction with an error of 100 gets squared to 10,000 in both calculations. In EMQ, that 10,000 is averaged with all the other squared errors. It dominates the result. In RMSE, you average the squared errors first (same 10,000), but then you take the square root. That square root compresses the blow. A 10,000 squared error becomes a 100 RMSE contribution. The relative weight of that outlier is exactly the same in terms of the squared term, but the final RMSE number feels more grounded.
Here's where it gets juicy.
What RMSE Actually Tells You (That EMQ Hides)
RMSE gives you a rough sense of the standard deviation of the residuals. I said “rough,” because it's not exactly the same, but it's close. If your errors are normally distributed, RMSE approximates the standard deviation of the error distribution. That means you can use it to build confidence intervals. You can say, “About 68% of my predictions are within one RMSE of the true value.” You can't do that with EMQ directly because it's not in the same units as your data.
This is the hidden statistical difference between EMQ and RMSE error metrics that most tutorials skip. EMQ is a variance-like quantity. It measures the average power of the error. RMSE is a standard deviation-like quantity. It measures the typical magnitude of the error. They are not the same thing, even though they are directly convertible.
Think of it like distance. EMQ is like the area of a square. RMSE is the side length. One is squared, one is linear. You wouldn't tell someone your commute is “937 square kilometers” when you mean 30 kilometers. So why would you evaluate a model that way?
Why EMQ Loves Your Small Errors (And RMSE Doesn't)
Because squaring penalizes large errors disproportionately, both metrics are sensitive to outliers. But EMQ amplifies that sensitivity more in the final number. A model with one huge outlier and many tiny errors will have a sky-high EMQ. The same model might have a surprisingly reasonable RMSE because the square root pulls the number back down.
This creates a practical trap. If you minimize EMQ during training, your optimizer will absolutely destroy itself trying to fix that one outlier, potentially sacrificing performance on the 99 other data points. If you minimize RMSE, it still cares about the outlier, but the gradient is less aggressive. The statistical difference between EMQ and RMSE error metrics directly influences gradient behavior during optimization.
Seriously. This is not academic. I've seen teams spend weeks tuning hyperparameters on EMQ only to find their model became brittle on validation. Switching to RMSE as the primary metric often gave them a more robust model, even if the EMQ went up slightly.
How Outliers Expose the Real Statistical Difference Between EMQ and RMSE
Let's build a concrete example. You have 10 data points. Nine of them have small errors (like 1, 1, 1, 1, 1, 1, 1, 1, and 1). One has a massive error of 50.
- For EMQ: Square all errors (81 ones plus 2500 for the outlier). Average them. You get roughly 2502 / 10 = 250.2. - For RMSE: Take the same mean of squared errors (250.2), then square root it. You get roughly 15.8.
See the difference? The single outlier made EMQ skyrocket to 250.2. RMSE came in at 15.8. The statistical difference between EMQ and RMSE error metrics here is stark. EMQ says your model is terrible (average squared error of 250). RMSE says your typical error is around 16, which is still bad, but not apocalyptic.
The 'One Bad Data Point' Test
I call this the 'One Bad Data Point' test. It reveals the heart of the matter. EMQ is more punishing on outliers in its raw value. RMSE is still punishing (because the squaring still happened before the root), but the final number is more representative of the typical error magnitude if the outlier isn't the dominant story.
This doesn't mean RMSE is always better. It's a trade-off. If your application absolutely cannot tolerate large errors—say, you're predicting rocket telemetry or medical dosages—you might want to monitor EMQ specifically because it amplifies those catastrophic failures. But for most practical cases where you care about average performance across a distribution, RMSE is your friend.
Think about it like this. EMQ is the angry boss who only remembers your worst mistake. RMSE is the slightly more forgiving boss who factors in your good work too. Both remember the big screw-up, but EMQ never lets it go.
When You Should Deliberately Choose EMQ Over RMSE
There are scenarios where EMQ is the right call. If you are comparing models in terms of variance explained (like in ANOVA or regression decomposition), EMQ works directly with sums of squares. It's mathematically convenient. Also, if you are building a cost function where the cost is literally quadratic (e.g., financial penalties that scale with the square of the error), EMQ is the direct measure of that cost.
But for reporting to a business audience? For comparing model performance across different datasets with different scales? RMSE wins every time because of the unit alignment.
Here's the kicker: Many people use RMSE and EMQ interchangeably in casual conversation. They think the statistical difference between EMQ and RMSE error metrics is just a scaling factor. It's not. It's a difference in interpretation, outlier sensitivity, and gradient behavior. Ignore it at your own risk.
Practical Interpretation: Units, Scale, and Your Boss's Patience
I once had a client who insisted on reporting EMQ for a demand forecasting model. The numbers were enormous—millions of units squared. Every review meeting started with a gasp. “Your error is five million? That's insane!” I had to explain that the RMSE was only 2,200 units, which was about 5% of the average daily demand. That changed the conversation entirely.
This is the hidden cost of ignoring the statistical difference between EMQ and RMSE error metrics. You lose the ability to communicate effectively. You can't visually estimate whether a change in EMQ from 100 to 90 is meaningful. But a change in RMSE from 10 to 9.5? That's a 5% improvement. Intuitively clear.
The Unit Problem Nobody Talks About
Here is a quick checklist of why units matter:
- EMQ is in squared units. Hard to visualize.
- RMSE is in original units. Easy to visualize.
- A model with EMQ of 100 could have an RMSE of 10 or 100, depending on the distribution of errors.
- You cannot compare EMQ across different target variables with different scales. RMSE still has that problem, but at least it's in the same scale as the data.
- Confidence intervals built around RMSE are intuitive. Confidence intervals built around EMQ require squaring the bounds. Nobody does that.
The statistical difference between EMQ and RMSE error metrics is not just about the math. It's about human cognition. We think in linear terms. We compare lengths, not areas.
The Mathematical Relationship (And Why It's Not Linear)
If you have a set of errors, RMSE = sqrt(EMQ). That seems trivial. But because of the convexity of the square root function (specifically Jensen's inequality), the RMSE will always be less than or equal to the square root of the maximum squared error, but greater than or equal to the mean absolute error. The relationship is not linear.
This means that as you improve a model, a reduction in EMQ of, say, 20% might correspond to a reduction in RMSE of only 10%, depending on the distribution of the errors. The statistical difference between EMQ and RMSE error metrics means they tell different stories about the same model improvement.
It's like measuring a city's poverty level by average income versus median income. Both use the same data, but they highlight different aspects. EMQ is the average squared distance from the truth. RMSE is the root of that average. They are siblings, not twins.
Common Questions About the Statistical Difference Between EMQ and RMSE Error Metrics
What is EMQ exactly, and how is it different from MSE?
In most practical contexts, EMQ stands for Error Mean Square, which is synonymous with Mean Squared Error (MSE). The statistical difference between EMQ and RMSE boils down to the square root operation. EMQ is the average of squared errors. RMSE is the square root of that average. Some fields use EMQ to refer to a specific variant in signal processing, but in machine learning, treat it as MSE.
Does a lower RMSE always mean a better model?
Not necessarily. A lower RMSE usually indicates lower typical error magnitude, which is good. But if you are comparing models on different datasets or with different target variable scales, RMSE is not directly comparable. Also, a model tuned to minimize RMSE might still have a high EMQ due to a few outliers. Context is everything.
Can I convert EMQ to RMSE directly?
Yes. The mathematical relationship is RMSE = sqrt(EMQ). However, this conversion only works if both metrics are calculated on the exact same set of errors. You cannot take the EMQ from one model and the RMSE from another and compare them directly. The statistical difference between EMQ and RMSE is preserved through the square root transformation.
Why does my RMSE look smaller than my EMQ?
Because the square root of a number is always smaller than the number itself (for numbers greater than 1). If your EMQ is 100, RMSE is 10. If your EMQ is 0.5, RMSE is about 0.707. For values less than 1, RMSE can actually be larger than EMQ. This is a common point of confusion when working with normalized targets.
Which metric should I use for my boss's report?
Use RMSE for the boss. It is interpretable, intuitive, and in the same units as your data. EMQ is better for internal technical discussions about model variance or for optimizing loss functions where quadratic penalties matter. The statistical difference between EMQ and RMSE means RMSE is generally the safer choice for stakeholder communication.